
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 정처기실기
- 코딩
- 정처기
- 정보처리기사
- 리눅스자격증
- 리눅스
- C
- IT
- 리눅스활용
- 정보처리기사기출
- Linux
- python
- 머신러닝
- 공부블로그
- 웹개발
- 리눅스마스터2급
- 리눅스마스터2급2차
- SW
- 정보처리기사실기
- 정처기기출
- 리눅스명령어
- 프로그래밍
- IT자격증
- 자격증
- 파이썬
- Django
- 기사자격증
- 장고
- 리눅스마스터
- Java
- Today
- Total
Tech Trail
[AI] 머신러닝 알고리즘(1): Linear Regression, Logistic Regression, KNN, Decision Tree, Random Forest 본문
[AI] 머신러닝 알고리즘(1): Linear Regression, Logistic Regression, KNN, Decision Tree, Random Forest
_밍지_ 2023. 11. 19. 00:00머신러닝 주요 알고리즘
scikit-learn: 가장 인기 있는 머신러닝 패키지로, 다양한 머신러닝 알고리즘이 내장되어 있습니다.
머신러닝 주요 알고리즘 분류
회귀 (Regression)
- 예시: 선형 회귀 (Linear Regression)
- 코드 예시
from sklearn.linear_model import LinearRegression
model = LinearRegression()
분류 (Classification)
- 예시: 로지스틱 회귀 (Logistic Regression)
- 코드 예시
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
회귀와 분류 모두 가능
- 결정 트리 (Decision Tree)
- 랜덤 포레스트 (Random Forest)
- K-Nearest Neighbor (K-NN)
Linear Regression (선형 회귀)
예측하는 작업을 간단히 수행하는 알고리즘입니다. 입력 변수와 출력 변수 간의 관계를 찾습니다.
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
pred = model.predict(X_test)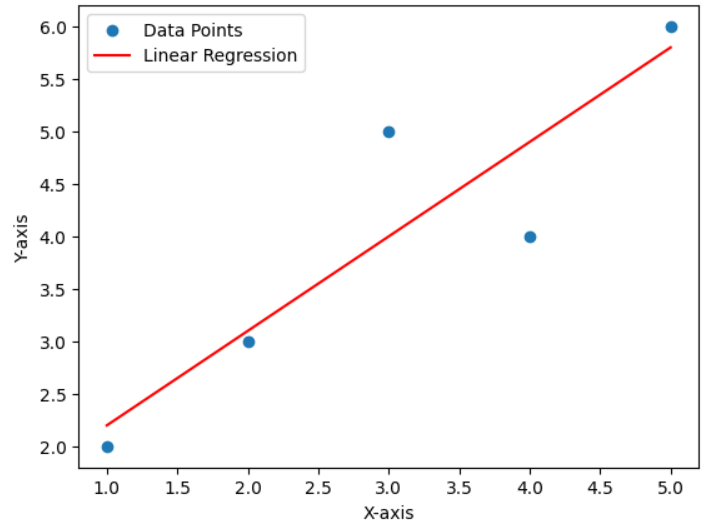
- 선형 회귀는 입력 변수(X)와 출력 변수(Y) 간의 선형 관계를 모델링하는 데 사용됩니다. 이 모델은 데이터를 가장 잘 설명하는 직선을 찾으려 노력합니다.
- 직선의 방정식은 Y = aX + b로 나타낼 수 있으며, 이 때 "a"는 기울기(선의 기울기)이고 "b"는 y 절편(선의 y축 교차점)입니다.
- 모델은 데이터 포인트와 예측된 선 간의 오차를 최소화하는 방향으로 학습됩니다. 이 오차를 최소화하기 위해 가장 적절한 "a"와 "b"를 찾습니다.
- 학습된 모델을 사용하여 새로운 X 값이 주어지면, 해당 X 값에 대한 Y 값을 예측할 수 있습니다.
Logistic Regression (로지스틱 회귀)
로지스틱 회귀는 주로 두 개의 클래스(0과 1)를 구분하는 이진 분류 작업에 사용되며, 일반 선형 회귀 모델을 사용하기 어렵기 때문에 로지스틱 함수를 활용하여 로지스틱 회귀 곡선을 생성합니다.
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
pred = model.predict(X_test)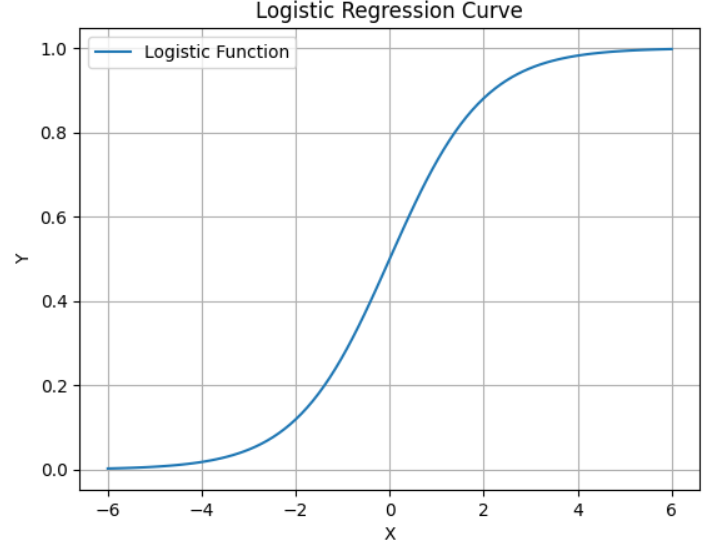
- 로지스틱 회귀는 주로 이진 분류 문제에서 사용되며, 로지스틱 함수를 사용하여 확률 값을 예측하는 데 효과적입니다.
- 로지스틱 함수는 S 모양의 곡선으로 나타나며, 이 곡선은 X 값에 대한 Y(확률) 값을 나타냅니다. X 값이 작을 때 Y 값은 거의 0에 가깝고, X 값이 커질수록 Y 값은 1에 가까워집니다. 즉 그래프의 왼쪽 끝에서는 "아니오"로 예측할 가능성이 높습니다. 오른쪽 끝에서는 "예"로 예측할 가능성이 높습니다.
- 로지스틱 회귀 모델은 입력 특징과 가중치의 조합을 사용하여 클래스 1에 속할 확률과 클래스 0에 속할 확률을 예측합니다. 그래프의 중간에서는 두 결과 중 하나를 예측하기가 어렵습니다. 이 지점은 50%의 가능성을 나타냅니다. 결국, 임계값(일반적으로 0.5)을 기준으로 이러한 확률을 사용하여 새로운 데이터가 어떤 클래스에 속할지를 예측합니다.
K-Nearest Neighbor (K-NN)
주변 이웃 데이터 포인트를 기반으로 분류 또는 회귀를 수행하는 알고리즘으로, 단순하면서도 효과적입니다. K-Nearest Neighbor (KNN) 알고리즘은 복잡한 데이터셋과 고차원 데이터에는 적합하지 않습니다.
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
pred = knn.predict(X_test)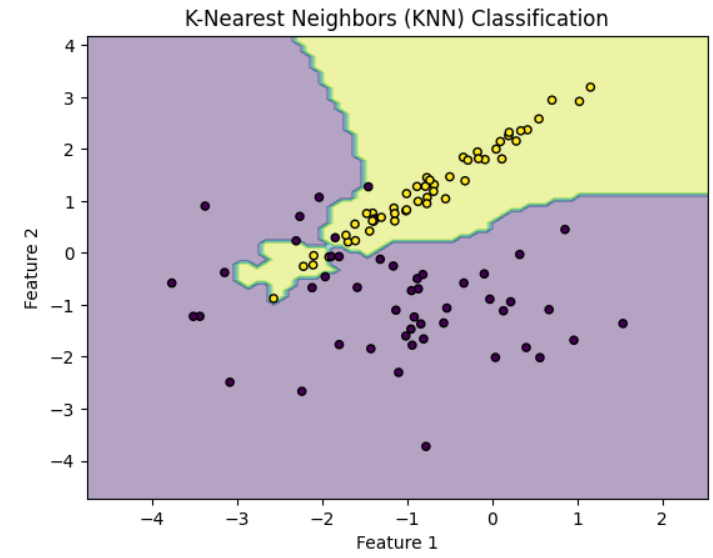
그래프 설명
- 그래프는 2차원 공간 상의 가상 데이터를 보여줍니다. X축과 Y축은 두 개의 특징(Feature 1 및 Feature 2)을 나타냅니다.
- 그래프에는 두 가지 클래스가 존재하며, 각 클래스는 다른 색상으로 표시됩니다.
- 배경색으로 표시된 영역은 KNN 모델에 의해 분류된 결과를 나타내며, 분류 경계는 경계 주변의 색상 차이로 표시됩니다. 이러한 경계는 KNN 알고리즘이 주변 데이터 포인트를 기반으로 결정됩니다.
KNN 동작 원리
- KNN는 각 데이터 포인트를 주변에 가장 가까운 K개의 이웃 데이터 포인트와 비교합니다. K 값은 사용자가 정의하며, 위의 예제에서는 K = 3으로 설정되었습니다.
- 각 데이터 포인트 주변의 K개 이웃 중 어떤 클래스가 많은지를 확인하여 해당 데이터 포인트를 해당 클래스로 예측합니다. 이것은 다수결 투표와 같은 원리입니다.
Decision Tree (결정 트리)
결정 트리는 분류와 회귀 작업 모두 가능한 다재다능한 머신러닝 알고리즘입니다. 이 알고리즘은 복잡한 데이터셋도 학습할 수 있으며, 랜덤 포레스트와 같은 강력한 머신러닝 알고리즘의 기본 구성 요소로 사용됩니다.
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=2)
model.fit(X_train, y_train)
pred = model.predict(X_test)
Random Forest (랜덤 포레스트)
랜덤 포레스트(Random Forest)는 여러 예측기(분류 및 회귀 모델)로부터 예측을 수집하여 하나의 예측 모델보다 뛰어난 예측을 얻을 수 있는 알고리즘입니다. 이 알고리즘은 일련의 예측기를 앙상블(ensemble)하여 사용하며, 결정 트리의 앙상블로서 랜덤 포레스트를 구성합니다.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=50)
model.fit(X_train, y_train)
pred = model.predict(X_test)'AI > Machine Learning' 카테고리의 다른 글
| [AI] 머신러닝 알고리즘(2): Ensemble 기법, XGBoost, LightGBM (0) | 2023.11.19 |
|---|
