
Notice
Recent Posts
Recent Comments
Link
250x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 머신러닝
- AI
- IT자격증
- 장고
- 정보처리기사기출
- 기사자격증
- 리눅스명령어
- Java
- 리눅스
- Linux
- 코딩
- 정보처리기사
- 리눅스마스터2급2차
- Django
- 리눅스마스터2급
- 웹개발
- 정처기기출
- IT
- 리눅스마스터
- 프로그래밍
- 정보처리기사실기
- 공부블로그
- C
- 리눅스활용
- 정처기
- python
- 리눅스자격증
- 정처기실기
- SW
- 자격증
Archives
- Today
- Total
Tech Trail
[NLP(자연어 처리)] 영화 리뷰 데이터 분석과 시각화: TensorFlow, Pandas, Matplotlib 등 본문
728x90
SMALL
영화 리뷰 데이터를 로드하고, 전처리 및 시각화하는 과정을 보여드리겠습니다.
목표
- TensorFlow, Pandas, Matplotlib 등의 라이브러리를 사용하여 데이터를 처리
- IMDb 데이터셋을 사용하여 긍정 및 부정 리뷰를 분석하고, 데이터의 분포와 특성을 파악
1. 데이터 로드
먼저, 필요한 라이브러리를 임포트합니다.
import os
import re
import pandas as pd
import tensorflow as tf
from tensorflow.keras import utils
- os: 디렉토리 작업
- re: 정규 표현식
- pandas: 데이터 조작
- tensorflow와 tensorflow.keras.utils: 데이터 다운로드 및 로드
IMDb 영화 리뷰 데이터셋을 다운로드하고 압축을 해제합니다.
data_set = tf.keras.utils.get_file(
fname="imdb.tar.gz", # 다운로드할 파일의 이름
origin="http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz",
extract=True # 압축 해제 여부
)
2. 데이터 디렉토리에서 데이터 로드
디렉토리에서 데이터를 로드하는 함수를 정의합니다.
def directory_data(directory):
data = {}
data["review"] = []
for file_path in os.listdir(directory):
with open(os.path.join(directory, file_path), "r", encoding='utf-8') as file:
data["review"].append(file.read())
return pd.DataFrame.from_dict(data)
directory_data 함수는 지정된 디렉토리에서 파일을 읽어와 리뷰 내용을 data["review"] 리스트에 추가한 후, 이를 Pandas DataFrame으로 변환합니다.
긍정 리뷰와 부정 리뷰를 로드하고 라벨을 추가합니다.
def data(directory):
pos_df = directory_data(os.path.join(directory, "pos"))
neg_df = directory_data(os.path.join(directory, "neg"))
pos_df["sentiment"] = 1
neg_df["sentiment"] = 0
return pd.concat([pos_df, neg_df])
훈련 데이터와 테스트 데이터를 각각 로드합니다.
train_df = data(os.path.join(os.path.dirname(data_set), "aclImdb", "train"))
test_df = data(os.path.join(os.path.dirname(data_set), "aclImdb", "test"))
3. 데이터 탐색 및 전처리
훈련 데이터의 상위 5개 행을 출력하여 데이터 구조를 확인합니다.
train_df.head()
리뷰 데이터를 리스트로 변환합니다.
reviews = list(train_df['review'])
리뷰를 토큰화하여 각 리뷰를 단어 리스트로 만들고, 각 리뷰의 토큰 길이와 알파벳 길이를 계산합니다.
tokenized_reviews = [r.split() for r in reviews]
review_len_by_token = [len(t) for t in tokenized_reviews]
review_len_by_alphabet = [len(s.replace(' ', '')) for s in reviews]
4. 데이터 시각화
히스토그램을 사용하여 리뷰 길이의 분포를 시각화합니다.
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 5))
plt.hist(review_len_by_token, bins=50, alpha=0.5, color='r', label='word')
plt.hist(review_len_by_alphabet, bins=50, alpha=0.5, color='b', label='alphabet')
plt.yscale('log', nonpositive='clip')
plt.title('Review Length Histogram')
plt.xlabel('Review Length')
plt.ylabel('Number of Reviews')
plt.legend()
plt.show()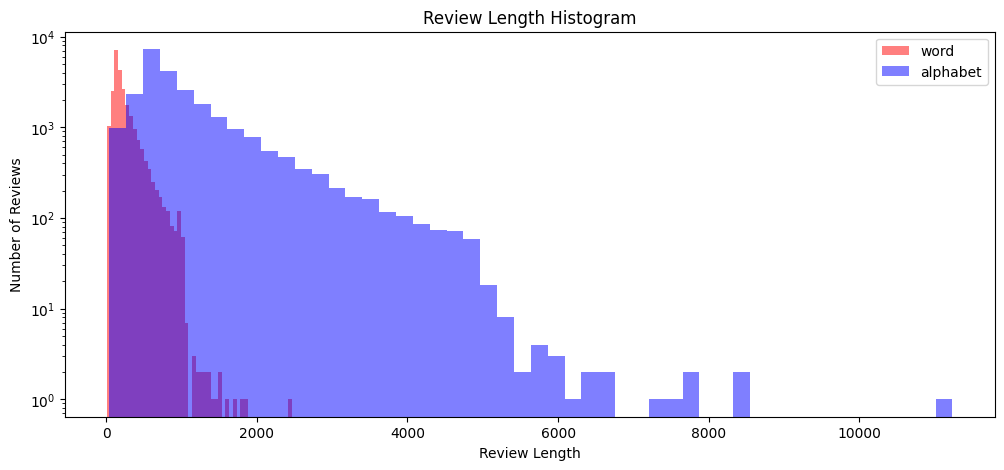
- 두 가지 히스토그램을 하나의 플롯에 그립니다. 하나는 단어 기준, 하나는 알파벳 기준 리뷰 길이입니다.
- 로그 스케일을 사용하여 y축을 설정합니다.
- 범례를 추가하여 그래프를 설명합니다.
리뷰 길이에 대한 다양한 통계치를 계산하고 출력합니다.
import numpy as np
print('문장 최대길이: ', np.max(review_len_by_token))
print('문장 최소길이: ', np.min(review_len_by_token))
print('문장 평균길이: ', np.mean(review_len_by_token))
print('문장 길이 표준편차: ', np.std(review_len_by_token))
print('문장 중간길이: ', np.median(review_len_by_token))
print('제 1 사분위 길이: ', np.percentile(review_len_by_token, 25))
print('제 3 사분위 길이: ', np.percentile(review_len_by_token, 75))
출력:
문장 최대길이: 2470
문장 최소길이: 10
문장 평균길이: 233.7872
문장 길이 표준편차: 173.72955740506563
문장 중간길이: 174.0
제 1 사분위 길이: 127.0
제 3 사분위 길이: 284.0
리뷰 길이에 대한 박스 플롯을 생성하여 분포를 시각화합니다.
plt.figure(figsize=(12, 5))
plt.boxplot([review_len_by_token], labels=['token'], showmeans=True)
plt.figure(figsize=(12, 5))
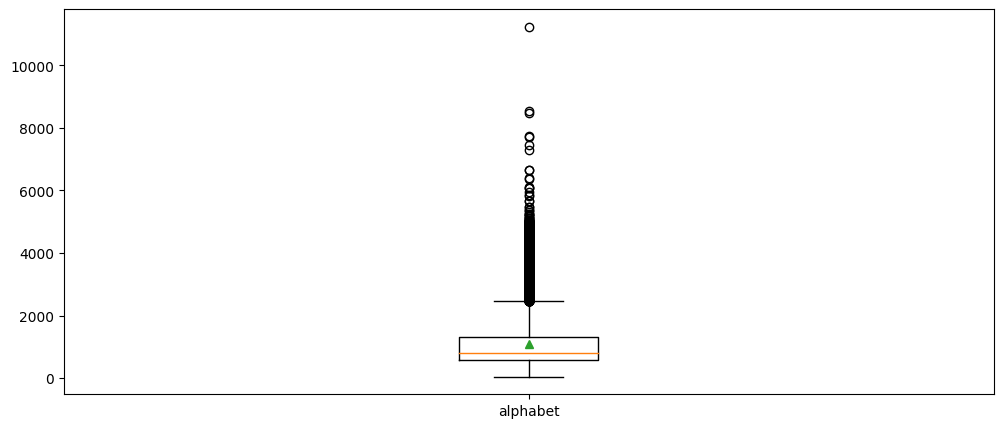
plt.boxplot([review_len_by_alphabet], labels=['alphabet'], showmeans=True)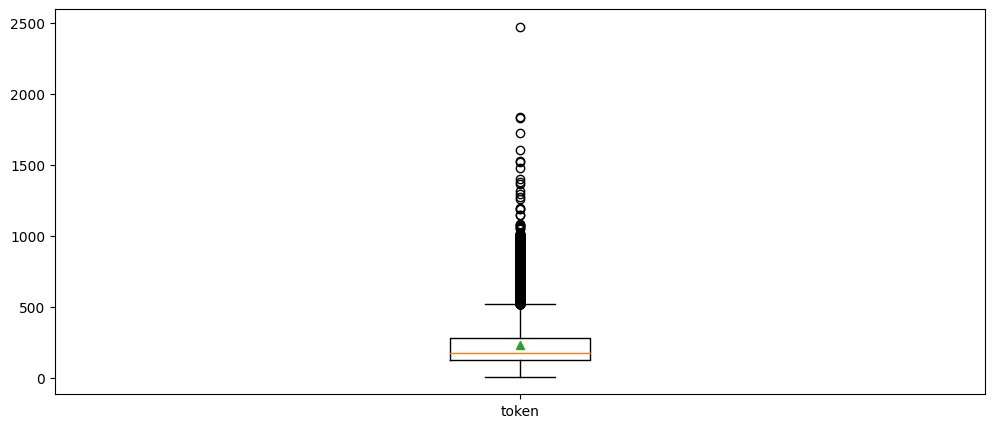
5. 워드 클라우드 생성
워드 클라우드를 생성하여 가장 많이 등장하는 단어를 시각화합니다.
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
wordcloud = WordCloud(stopwords=STOPWORDS, background_color='black', width=800, height=600).generate(' '.join(train_df['review']))
plt.figure(figsize=(15, 10))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()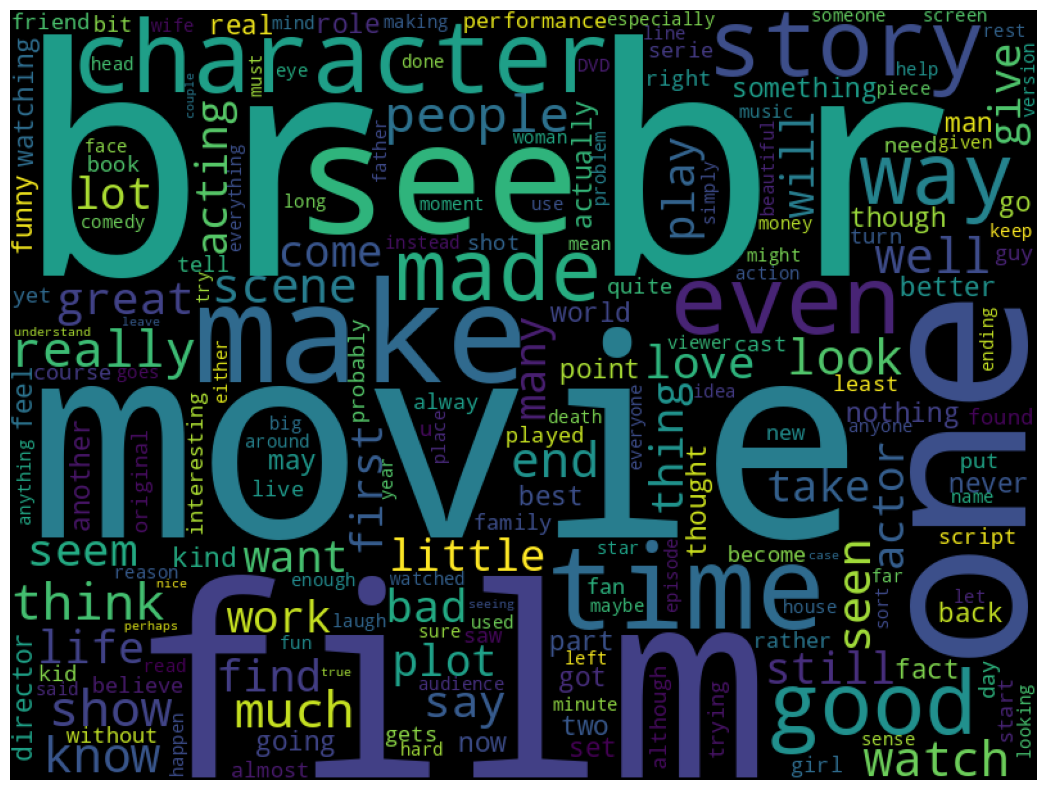
- STOPWORDS를 사용하여 불용어를 제거합니다.
6. 긍정/부정 리뷰의 분포 시각화
긍정과 부정 리뷰의 분포를 시각화합니다.
import seaborn as sns
import matplotlib.pyplot as plt
sentiment = train_df['sentiment'].value_counts()
fig, axe = plt.subplots(ncols=1)
fig.set_size_inches(6, 3)
sns.countplot(train_df['sentiment'])
plt.show()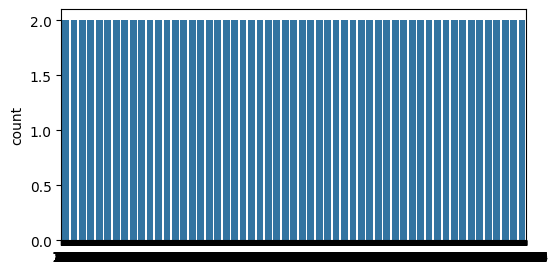
- seaborn 라이브러리를 사용하여 카운트 플롯을 생성합니다.
728x90
LIST
'AI > NLP' 카테고리의 다른 글
| [NLP(자연어 처리)] 검색 엔진을 위한 TF-IDF와 Similarity 연산 (1) | 2024.05.22 |
|---|