
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 장고
- 정처기
- 프로그래밍
- 머신러닝
- 리눅스활용
- 웹개발
- 정보처리기사
- 공부블로그
- 리눅스마스터2급2차
- IT자격증
- Django
- Java
- 정보처리기사실기
- 리눅스명령어
- 정보처리기사기출
- 리눅스자격증
- 정처기실기
- C
- 리눅스마스터
- 정처기기출
- SW
- python
- 기사자격증
- Linux
- 코딩
- 리눅스
- 자격증
- 리눅스마스터2급
- AI
- IT
- Today
- Total
Tech Trail
Overfitting in Machine Learning and Computer Vision (기계 학습에서 과적합 방지하는 방법) 본문
Overfitting in Machine Learning and Computer Vision (기계 학습에서 과적합 방지하는 방법)
_밍지_ 2024. 3. 27. 19:00Overfitting(과적합)은 모델이 학습 데이터에 정확히 핏 되는 경우입니다. 학습한 머신러닝 모델이 새로운 데이터와 보이지 않는 데이터를 이해하는 대신 학습 데이터에 과도하게 적합할 때 모델의 품질이 악화됩니다.
과적합이 발생할 수 있는 몇 가지 이유가 있으며 다양한 최신 기술을 적용하여 이러한 원인에 대응하는 것이 도움이 될 수 있습니다.
오늘 게시글에서는 과적합, 과적합의 일반적인 이유, 머신러닝 모델에서 과적합 감지 및 머신러닝 모델 학습에서 과적합을 방지하기 위한 몇 가지 사례를 알려드리겠습니다.
- 과적합이란?
- 과적합이 발생하는 방식
- 과적합을 감지하는 방법
- 과적합을 방지하는 방법
What is Overfitting?
Overfitting(과적합)은 모델이 학습 데이터에 정확히 핏되는 경우입니다. 과적합은 통계 모델이 모든 데이터 포인트 또는 표시된 데이터에 있는 필수 데이터 포인트보다 더 많은 데이터 포인트를 다루려고 할 때 발생합니다. 과적합이 발생하면 모델은 보이지 않는 데이터에 대해 매우 저조한 성능을 발휘합니다.
모델이 과적합되면 모델은 학습 데이터에 존재하는 너무 많은 노이즈와 부정확한 값을 학습하기 시작하고 향후 관측치를 예측하지 못하여 모델의 정밀도와 정확도를 떨어뜨립니다.
다음과 같은 경우를 생각해 볼 수 있습니다. 100개의 이미지가 있는데 50개는 고양이이고 50개는 개입니다. 이미지 분류 모델을 학습할 때 모델은 학습 데이터셋에 대해 99%의 정확도를 표시하지만 테스트 세트에 대한 정확도는 45%에 불과하므로 모델이 과적합되었음을 나타냅니다.
즉, training set 샘플에서 개의 그림을 제공하면 모델이 클래스를 정확하게 예측하는 반면, 인터넷에서 임의의 개 이미지가 제공되면 모델이 올바른 출력을 제공하지 못합니다.
기계 학습 분류 모델이 과적합된 거죠. 분류기는 고양이와 개의 특정 특징을 식별하는 방법을 학습했지만, 모델은 보이지 않는 이미지에서 성능을 발휘할 수 있을 만큼 충분한 일반적인 특징을 학습하지 못했습니다. 따라서 이 모델은 결과를 신뢰할 수 없으므로 실제 사용에 사용할 준비가 되어 있지 않습니다.

How does overfitting happen?
머신러닝 모델에서 과적합이 나타날 수 있는 몇 가지 이유가 있습니다. 과적합의 가장 일반적인 원인 중 일부에 대해 논의해 보겠습니다.
- 모델의 분산이 높고 편향이 낮으면 훈련 정확도는 증가하지만 검증 정확도는 Epoch 수에 따라 감소합니다.
- 데이터 세트에 노이즈가 있는 데이터나 부정확한 점(garbage values)이 있는 경우 검증 정확도가 감소하고 분산이 증가할 수 있습니다.
- 모형이 너무 복잡하면 분산이 증가하고 bias가 낮아집니다. 학습 데이터를 사용하여 너무 많은 노이즈 또는 무작위 변동을 학습할 수 있으며, 이는 모델이 이전에 본 적이 없는 데이터의 성능을 방해합니다.
- 학습 데이터 세트의 크기가 적절하면 모델은 일부 시나리오 또는 가능성만 탐색하게 됩니다. 보이지 않는 데이터에 도입되면 예측의 정확도가 떨어집니다.
Detect overfitting in machine learning models
과적합 검출은 데이터를 테스트하기 전에 수행하는 복잡한 작업입니다. 가장 좋은 방법은 가능한 한 빨리 데이터 테스트를 시작하여 모델이 작동할 데이터 세트에서 잘 수행될 수 있는지 여부를 파악하는 것입니다.
여기서 핵심은 "내 모델이 보이지 않는 데이터에서 잘 수행되는가"것입니다. 보이지 않는 데이터에서 모델의 성능이 좋지 않고 해당 데이터가 모델에 제공할 데이터의 종류를 나타내는 경우 과적합이 발생했을 수 있습니다.
그러나 몇 가지 사항은 모델이 학습 데이터 세트에서 너무 많이 학습하고 과적합될 것임을 나타냅니다.
데이터 세트를 train, validation, and test로 분할할 때 데이터 세트가 random으로 되어 있는지 확인해야 합니다. 이것이 핵심입니다. 데이터 세트가 특정 속성(예: 평방미터 단위의 집 크기)을 기준으로 정렬되는 경우 학습 데이터 세트는 검증 및 테스트 세트에만 나타나기 때문에 극단적인 경우(대규모 집 크기)에 대해 학습하지 못할 수 있습니다.
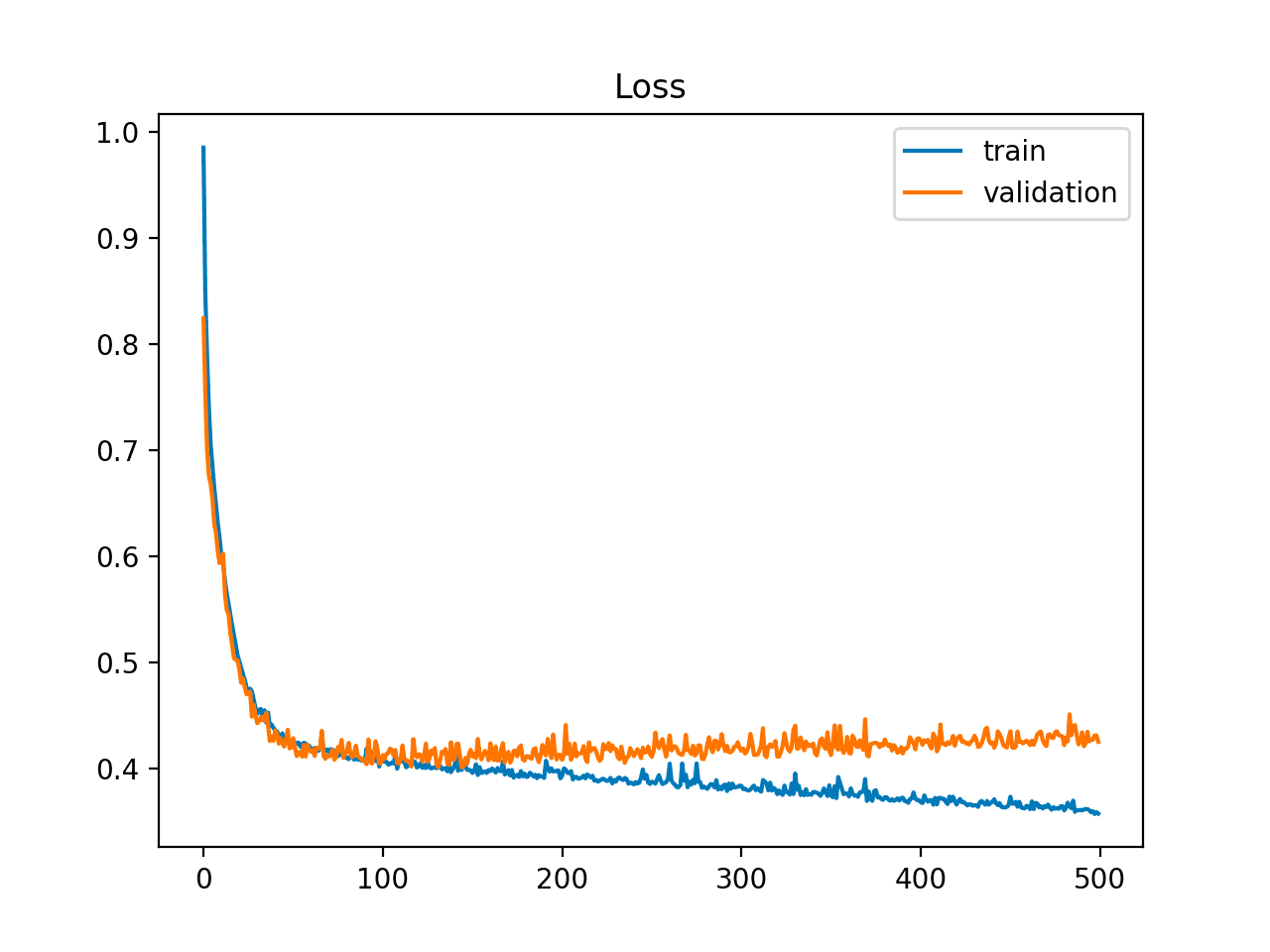
또한 학습 곡선은 생각보다 많은 정보를 제공할 수 있습니다. 학습 곡선은 시간 경과에 따른 모델 학습 성능의 플롯으로, y축은 학습의 일부 메트릭(분류 정확도 또는 분류 손실)이고 x축은 경험(시간)입니다. 반복 횟수가 증가함에 따라 훈련 오차가 감소하는 경우, 검증 오차는 변경되거나 증가하지 않습니다. 이는 모델이 과적합되고 있음을 나타내며 훈련을 중지할 수 있습니다.
How to Prevent Overfitting
기계 학습 모델은 관련된 매개 변수 수의 복잡성으로 인해 과적합되기 쉽습니다. 과적합을 방지하는 데 사용되는 방법을 이해하는 것이 중요합니다.
Add More Training Data
더 많은 학습 데이터를 추가하는 것은 해당 데이터를 처리하기 위해 더 많은 데이터와 컴퓨팅 리소스에 액세스 할 수 있는 경우 분산을 해결하는 가장 간단한 방법입니다. 데이터가 많을수록 기계 학습 모델이 데이터 세트의 이미지와 관련된 기능 대신 보다 일반적인 기능을 이해하는 데 도움이 됩니다. 모델이 식별할 수 있는 일반적인 특징이 많을수록 모델이 보이는 이미지에서만 잘 작동할 가능성이 줄어듭니다.
Use Data Augmentation
더 많은 데이터에 액세스할 수 없는 경우 데이터를 증강하는 것이 좋습니다. 데이터 증강을 사용하면 기존 데이터 세트에 다양한 변환을 적용하여 데이터 세트 크기를 인위적으로 늘릴 수 있습니다. 증강은 특히 컴퓨터 비전에서 모델의 데이터 샘플 크기를 늘리는 일반적인 기술입니다.

Standardization
각 피처가 0의 평균과 단위 분산을 갖도록 특징을 표준화합니다. 학습 알고리즘 속도를 높이기 위한 변경 사항입니다. 정규화된 입력값이 없으면 가중치가 크게 변하여 과적합과 높은 분산이 발생할 수 있습니다.
Feature Selection
흔히 저지르는 실수는 각 피처에 사용할 수 있는 포인트 수에 관계없이 자신이 가지고 있는 피처의 대부분 또는 전부를 포함하는 것입니다. 피처의 표본 크기가 작으면 모델이 특성이 데이터 집합의 데이터에 더 일반적으로 적용되는 방식을 이해하기 어렵기 때문에 문제가 발생합니다.
스스로에게 질문해 보세요. 당신의 데이터 셋에 피처는 많지만 각 피처에 대한 데이터 포인트는 적습니까? 이 경우 학습에 필요한 필수 피처만 선택하는 것이 좋습니다.
Cross-Validation
교차 검증을 사용하면 데이터셋을 k-그룹으로 분할하고 각 그룹을 테스트 세트로 설정하여 모든 데이터를 학습에 사용할 수 있습니다. 각 그룹에 대해 k번 과정을 테스트 세트로 반복합니다.

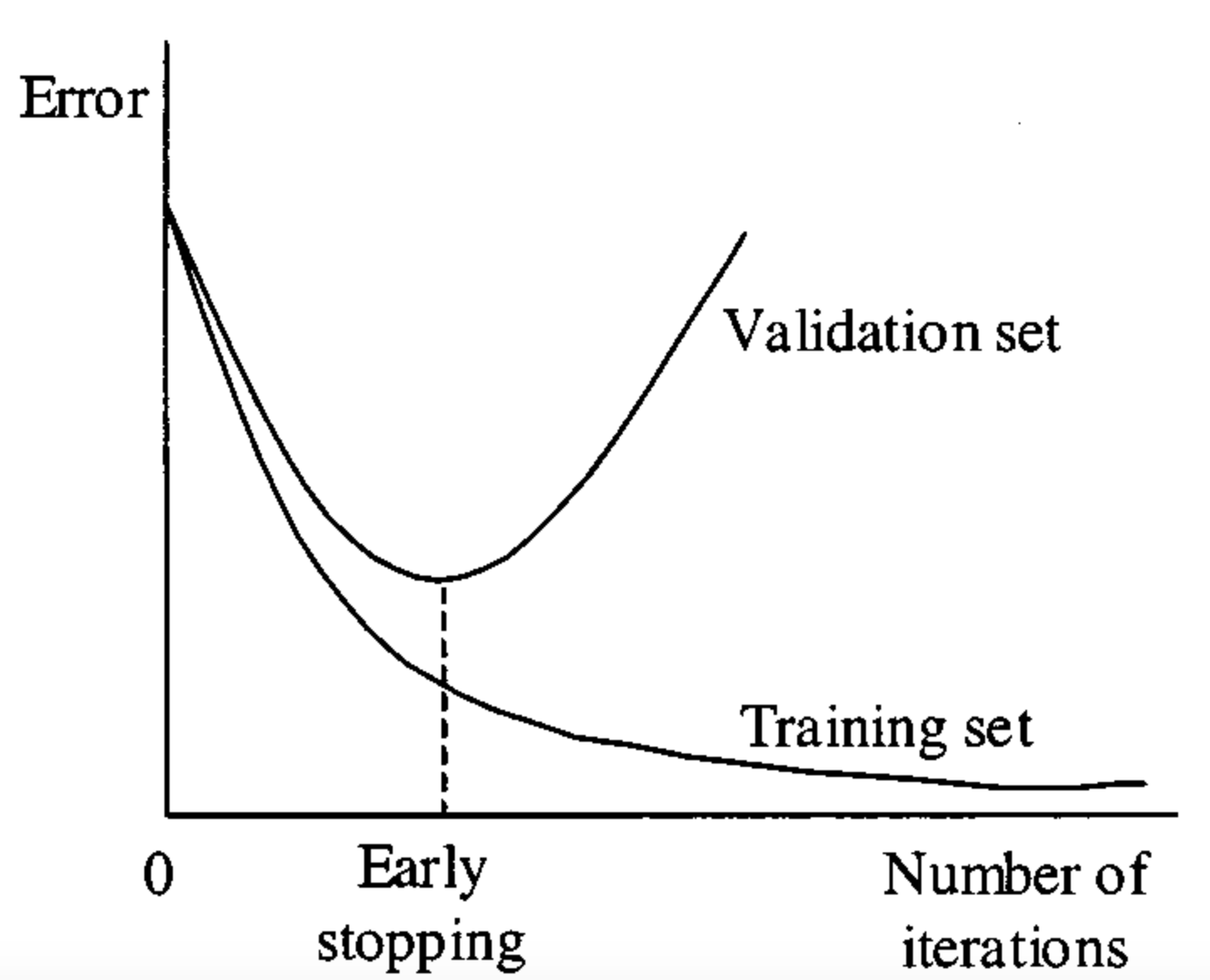
Early Stopping
학습 프로세스를 중지해야 하는 시점은 validation loss(검증 손실)이 증가하기 시작할 때입니다. 학습 곡선을 모니터링하거나 early stopping trigger를 설정하여 이를 구현할 수 있습니다.
자신에게 가장 적합한 것이 무엇인지 파악하기 위해 다양한 중지 시간들을 실험해봐야 합니다. 이상적인 상황은 모델이 데이터 세트에서 노이즈 학습을 시작할 것으로 예상하기 직전에 훈련을 중지하는 것입니다. 여러 번 훈련하고 소음이 훈련에 영향을 미치기 시작하는 지점을 대략적으로 파악하여 이를 수행할 수 있습니다. 훈련 그래프는 훈련을 중단할 최적의 시간을 알려주는 데 도움이 됩니다.
기억하세요. 너무 일찍 훈련을 중단하면 모델이 조금 더 오래 훈련할 때만큼 성능이 떨어질 수 있습니다.
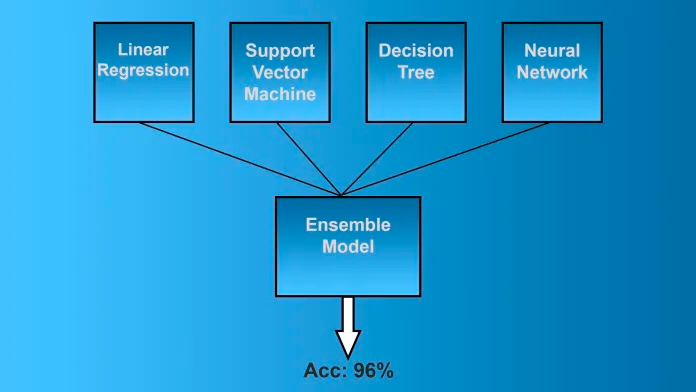
Ensembling
이 기술에서 classifiers 또는 experts와 같이 전략적으로 생성된 여러 모델을 결합하여 더 나은 예측 성능을 얻습니다. 분산을 줄이고, 모델링 방법 편향을 최소화하고, 과적합 가능성을 줄입니다.
Regularization
이것은 머신러닝에서 유행하는 기술로, 편향을 약간만 늘리면서 분산을 크게 줄여 모델의 복잡성을 줄이는 것을 목표로 합니다. 가장 널리 사용되는 정규화 방법은 L1(Lasso), L2(Ridge), Elastic Net, Dropout, Batch Normalization 등입니다.

Can Overfitting in Machine Learning Be A Good Outcome?
머신러닝 모델의 과적합은 일반적으로 금기시되지만, 오늘날 컴퓨터 비전 모델이 나중에 비즈니스 애플리케이션에 배포될 위험을 제거하려고 할 때 일반적입니다. 컴퓨터 비전 프로젝트에 시간과 노력을 투자하기 전에 조직은 작업이 모델에서 "학습 가능"한 지 확인하고 싶을 수 있습니다.
이 작업은 과적합 모델을 만들어 수행할 수 있습니다. 나타나는 객체의 하위 집합을 식별하는 데 집중하는 이미지를 수집한 후에는 구조가 다양하지 않은 학습 및 검증 이미지로 모델을 로드하게 됩니다. 이렇게 하면 모델이 학습 이미지에서 식별한 레이블이 지정된 개체를 감지하는 데 최적화되므로 해당 환경에 과적합됩니다.
학습 가능한 작업으로서 위험을 완전히 제거한 프로젝트는 비즈니스에서 구현할 수 있는 실행 가능한 컴퓨터 비전 프로젝트가 있음을 의미합니다. 작업자 안전, 결함 감지, 문서 구문 분석, 객체 추적, 방송 경험, 게임, 증강 현실 앱 등 사용 사례가 무엇이든... 때때로 과적합은 비전이 문제에 대한 현실적인 해결책인지 확인하는 데 필요한 증거가 됩니다.
Conclusion
과적합은 기계 학습 분야에서 끊임없는 문제입니다. 일반적인 이유와 과적합을 감지하는 방법을 이해하는 것은 어렵습니다. 오늘 게시물에서 논의된 표준 사례는 모델 학습에서 과적합을 해결하는 방법을 이해하는 데 도움이 될 겁니다.
위 글은 Mrinal Walia의 글을 기반으로 작성하였습니다.



